Искусственный интеллект — глаза и уши людей будущего

Искусственный интеллект неуклонно наступает на местами стройные, местами разрозненные ряды узких и широких специалистов разных мастей и профилей. У кого-то это вызывает беспокойство, кто-то относится к такому наступлению весьма скептически. Но факт заключается в том, что ареал обитания искусственного интеллекта постоянно расширяется. Переводческая отрасль — не исключение.
Цель исследования: разобраться со сложностями технологии распознавания речи, дать понятие термину «искусственный интеллект «. Найти различия между распознаванием письменной и устной речи.
Каковы перспективы совершенствования процесса распознавания искусственным интеллектом письменной и устной речи.
Гипотеза исследования: разработка технологий искусственного интеллекта идеального распознавания человеческой речи может привести к привести к «слепоте» и безграмотности человечества.
Задачи исследования:
- дать понятие термину «искусственный интеллект
- проанализировать сложности технологии распознавания письменной и устной речи искусственным интеллектом.
- выявить сферы человеческой деятельности где распознавания речи крайне необходимо.
какие потенциальные возможности предоставит искусственный интеллект людям с проблемами слуха и речи? - Какие опасности может таить в себе неконтролируемый искусственный интеллект обладающий высоким качеством распознавания человеческой речи?
Методы исследования: исследовательский, частично-поисковый, репродуктивный.
План исследования:
Хронология событий:

- 1950 и 1960: Детский лепет
Первые системы распознавания речи могли понимать только цифры (учитывая сложность языка, это правильно, что инженеры сначала сфокусировались на цифрах). Bell Laboratories разработали систему «Audrey», которая распознавала цифры, сказанные одним голосом. Через 10 лет, в 1962 году, IBM продемонстрировала их детище — систему «Shoebox«, которая понимала 16 слов на английском.
- 1970-е: Системы постепенно приобретают популярность
Системы распознавания речи сделали большие шаги в семидесятых благодаря интересу и спонсированию от министерства обороны США. Их программа DARPA Speech Understanding Research (SUR) с 1971 по 1976 год была одной из самой большой в истории распознавания речи, и помимо всего остального она отвечала за систему «Harpy» Университета Карнеги Меллона. «Harpy» понимала 1011 слов, что является средним словарным запасом трехлетнего ребенка.
- 1980-е: Распознавание речи оправдывает прогнозы
В следующей декаде благодаря новым подходам и технологиям словарный запас подобных систем вырос с нескольких сотен до нескольких тысяч слов и имел потенциал распознавания неограниченного количества слов. Одной из причин был новый статистический метод, больше известный как скрытая марковская модель.
Используя шаблоны для слов и звуковые паттерны, она рассматривала вероятность того, что неизвестные звуки могли быть словами. Эта база использовалась другими системами еще на протяжении двадцати лет (Automatic Speech RecognitionA Brief History of the Technology Development).
- 2000-е: Застой в распознавании речи — пока не появился Google
К 2001 году распознавание речи поднялось до 80-процентной точности, и прогресс технологии остановился. Системы распознавали работали отлично, когда языковая вселенная была ограниченной, но они до сих пор «догадывались» при помощи статистических моделей среди похожих слов, языковая вселенная росла вместе с ростом Интернета.
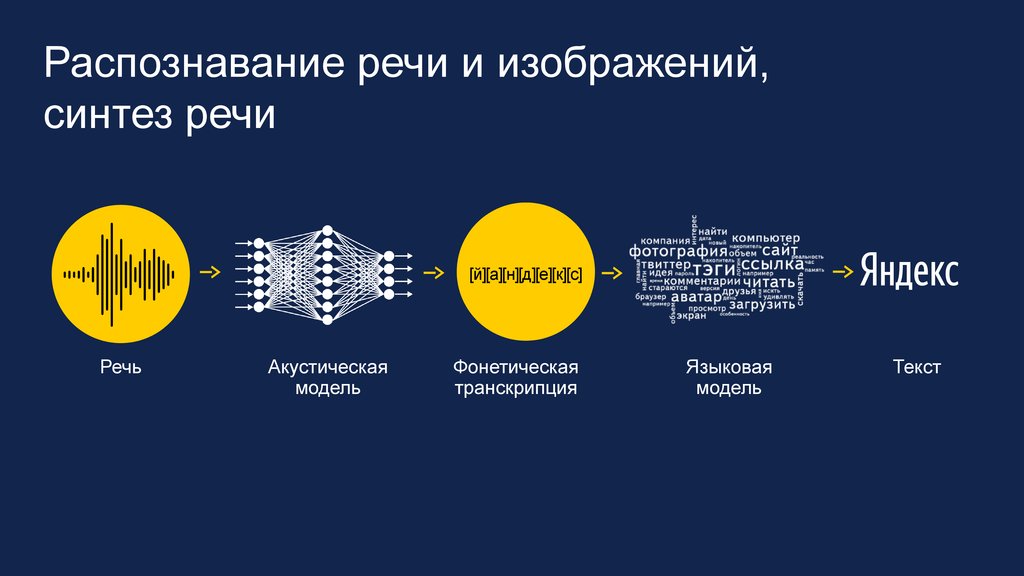
Распознавание голоса
Для измерения голоса программа использует ряд звуковых параметров: частоту и длину звуковой волны в определенный момент времени. К примеру, когда вы общаетесь с популярным голосовым помощником Alexa, ПО разбивает ваш голос на 25-миллисекундные слайды, а потом преобразует каждый из отрезков в цифровые сигнатуры. После этого сигнатурные блоки сравниваются с внутренним каталогом звуков программы, пока количество совпадений не будет достаточно высоким, чтобы ИИ «перевел» цифры в понятный ему буквенный запрос.

Перспективы распознавания речи
Алан Блэк из Институт языковых технологий имени Карнеги рассуждает о том, что для всех специалистов из крупных компаний наиболее интересным является поиск предела возможностей их собственной системы. «Когда программа говорит «Я не могу этого сделать», вот тогда ситуация становится по‑настоящему интересной», шутит он. Впрочем, это ив самом деле так: реагирование на непредсказуемые запросы пользователя даже является одной из основных задач, которую исследуют студенческие кружки, которые борются за премию Alexa Prize — а это целых 2,5 миллиона долларов. Их задача состоит в том, чтобы создать чат-бота, предназначенного для общения с людьми, задающими последовательные и осмысленные вопросы. Информация в данном случае обновляется раз в 20 минут. Звучит как довольно простая задача даже для рядового программиста, но на практике общение программы с живыми людьми всегда сопряжено с отступлениями от темы диалога, спонтанными фразами и прочими нарушениями. Программа, которая научится работать с ними так же хорошо, как реальный человек, станет огромным прорывом для всей индустрии ИИ.
Голос искусственного интеллекта
Интересные факты о речи, которую распознает искусственный интеллект
1. Во время разговора наш организм включает в работу около ста мышц груди, шеи, челюстей, щёк, языка и губ. Каждая из этих мышц состоит из сотен и даже тысяч мышечных волокон. Чтобы запустить весь этот сложный механизм, необходимо большее количество нейронов, чем в процессе ходьбы или бега.
2. Человек может произнести до 14 звуков в секунду, в это время органы артикуляционного аппарата (язык, губы и челюсти) могут совершать всего от двух до четырех движений за одну секунду.
3. Согласно наблюдениям американских учёных, у человека есть особый ген, который отвечает за логическое построение фраз и их понимание.
4. В современном мире известно о существовании более 6 тысяч языков.
5. Звук «А» является самым распространённым в мире звуком. Он есть во всех языках нашей планеты.
6. Удивительным является тот факт, что ребёнок с самого рождения уже различает звуки речи. Дело в том, что способность, которая позволит ему в будущем понимать родную речь, закладывается ещё в утробе матери.
Вывод: благодаря искусственному интеллекту можно облегчить поглощаемый объем информации,сделать его более доступный и понятным.
- https://habr.com/ru/post/131945/
- https://www.bestreferat.ru/referat-393322.html
- https://www.bibliofond.ru/view.aspx?id=871454
10/10 лучший проект!!!!!